Code
Supplementeray document containing achitecture-specific details can be found here.
Code and building blocks of GlideNet can be found here.
CAR Dataset can be accessed through the API here.
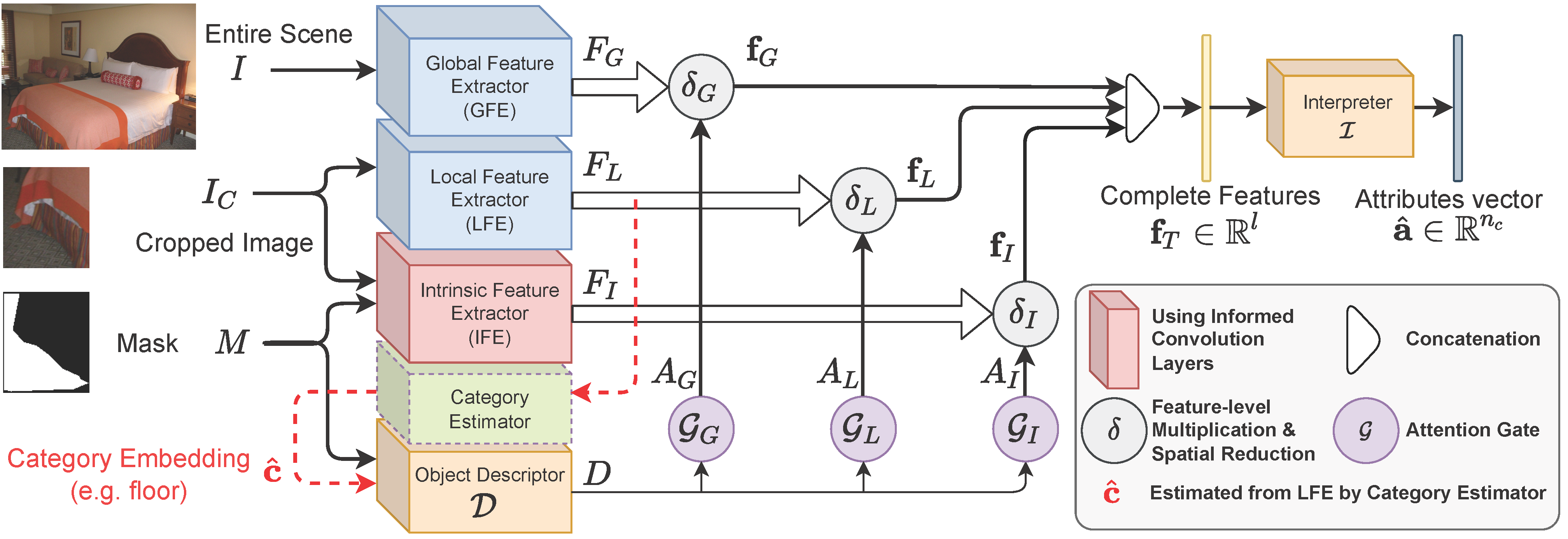
GlideNet Structure
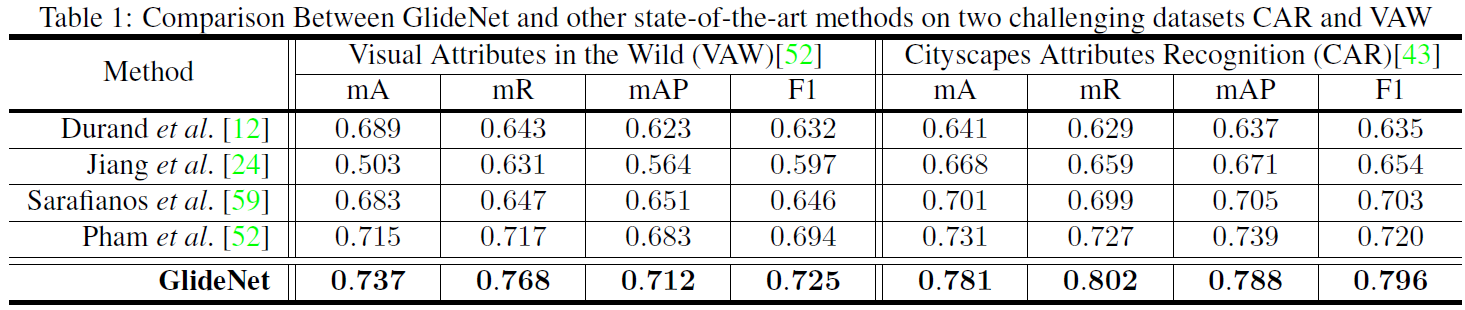
Results
Related Publications
K. Metwaly, A. Kim, E. Branson, and V. Monga, “GlideNet: Global, Local and Intrinsic based Dense Embedding NETworkfor Multi-category Attributes Prediction”, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022. [arXiv]
K. Metwaly, A. Kim, E. Branson, and V. Monga, “CAR - Cityscapes Attributes Recognition A Multi-category Attributes Dataset for Autonomous Vehicles”, arxiv, 2022. [arXiv]
Selected References
Khoi Pham, Kushal Kafle, Zhe Lin, Zhihong Ding, ScottCohen, Quan Tran, and Abhinav Shrivastava "Learning to predict visual attributes in the wild," in Proc. IEEE Conf. on Comp. Vis. Patt. Recog., 2021, pp 13018–13028.
Nikolaos Sarafianos, Xiang Xu, and Ioannis A Kakadiaris "Deep imbalanced attribute classification using visual attention aggregation," in Proc. Europ. Conf. Comp. Vis., 2018, pp. 680–697.
Huaizu Jiang, Ishan Misra, Marcus Rohrbach, Erik Learned-Miller, and Xinlei Chen "In defense of grid features for visual question answering," in Proc. IEEE Conf. on Comp. Vis. Patt. Recog., 2020, pp. 10267–10276.
Thibaut Durand, Nazanin Mehrasa, and Greg Mori "Learning a Deep ConvNet for Multi-Label Classification With Partial Labels," in Proc. IEEE Conf. Comp. Vis. Patt. Recog., 2019, pp. 647–657.