RECENT PROJECTS
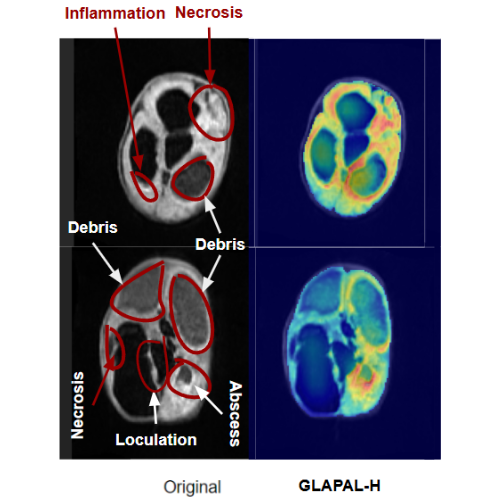
GLAPAL-H: Global, Local And Parts Aware Learner for Hydrocephalus Infection Diagnosis in Low-Field MRI
IEEE TBME
We develop GLAPAL-H, a multi-task deep learning model with global, local, and parts-aware segmentation branches for low-field MRI-based hydrocephalus classification and etiology modeling.
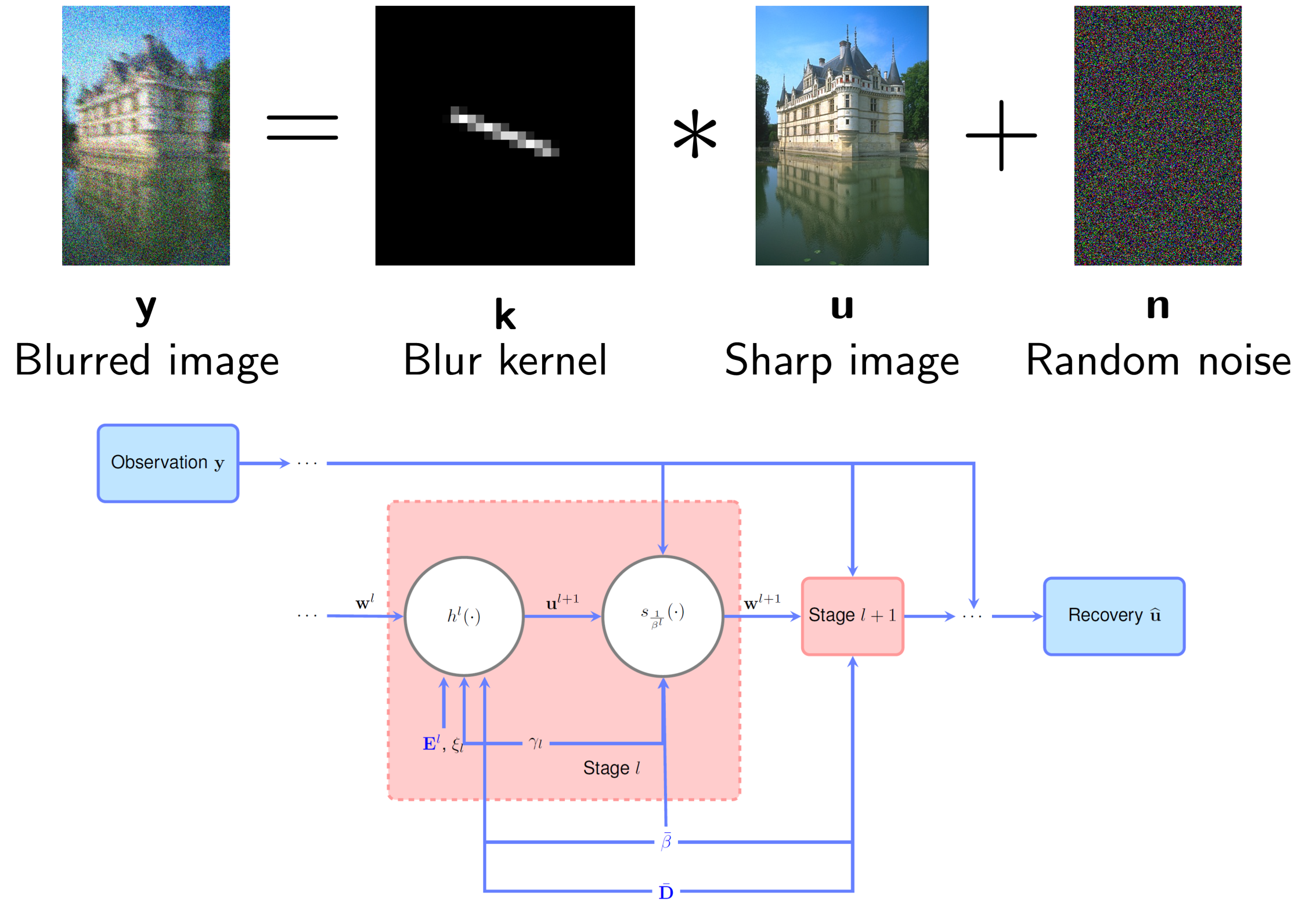
Deep, Convergent, Unrolled Half-Quadratic Splitting For Image Deconvolution
IEEE TCI
Though Imaging inverse problems have particularly benefited from unrolling-based interpretable deep network design, typical unrolling approaches heuristically design layer-specific convolution weights to improve performance. Crucially, convergence properties of the underlying iterative algorithm are lost once layer-specific parameters are learned from training data. We propose an unrolling technique that breaks the trade-off between retaining algorithm properties while simultaneously enhancing performance.
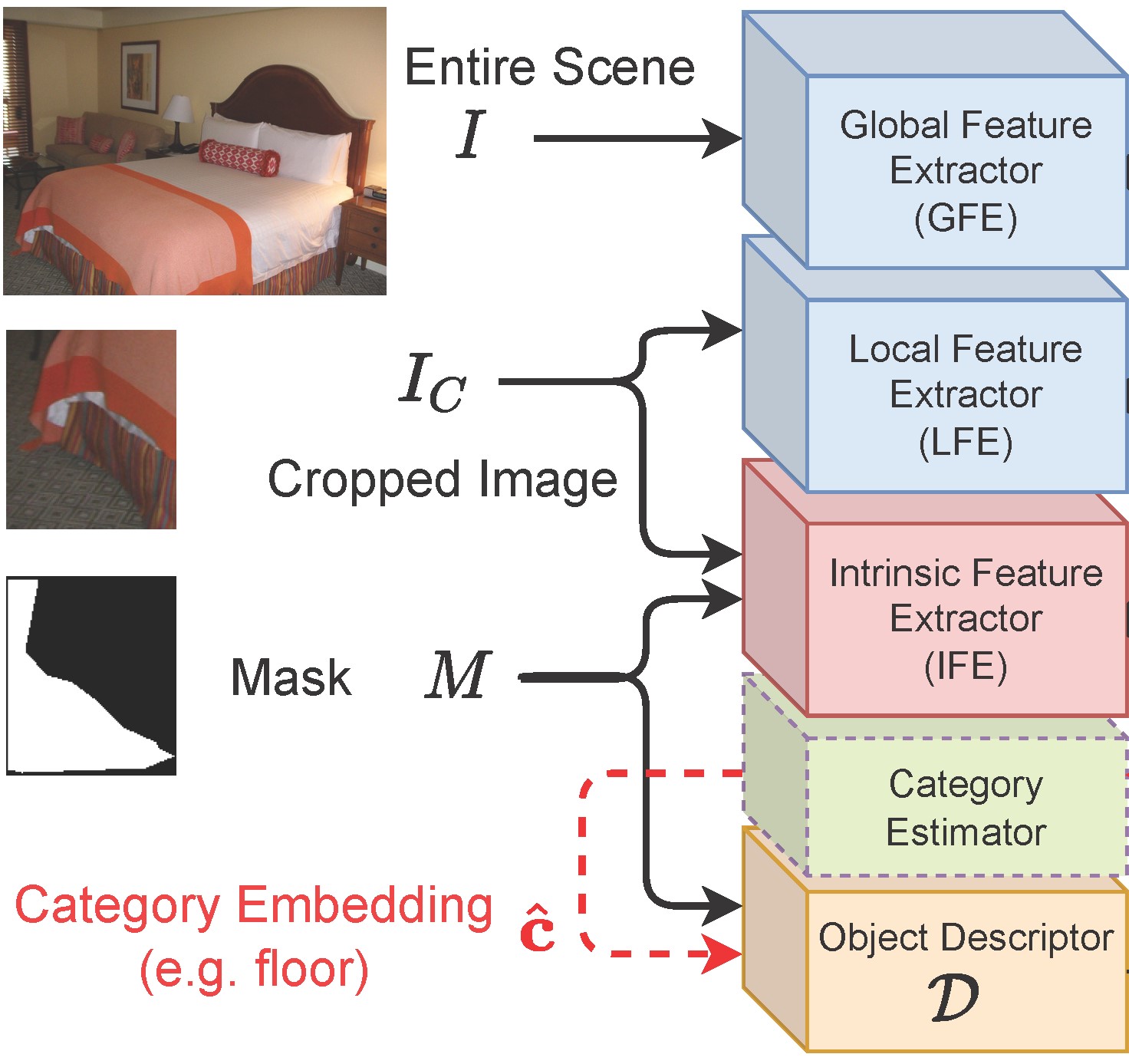
GlideNet for Multi-Category Attributes Prediction (CVPR 2022)
Attaching attributes (such as color, shape, state, action) to object categories is an important computer vision problem. Attribute prediction has seen exciting recent progress and is often formulated as a multi-label classification problem. Yet significant challenges remain in: 1) predicting a large number of attributes over multiple object categories, 2) modeling category-dependence of attributes, 3) methodically capturing both global and local scene context, and 4) robustly predicting attributes of objects with low pixel-count.
Robust Deep 3D Blood Vessel Segmentation Using Structural Priors
Deep learning has enabled significant improvements in the accuracy of 3D blood vessel segmentation. Open challenges remain in scenarios where labeled 3D segmentation maps for training are severely limited, as is often the case in practice, and in ensuring robustness to noise.

2021 NTIRE-CVPR Runner Up
Physically Inspired Dense Fusion Networks for Relighting
The project proposes a model which enriches neural networks with physical insight. More precisely, the proposed method generates the relighted image with new illumination settings via two different strategies and subsequently fuses them using a weight map. It outperforms many state-of-the-art algorithms.

Structural Prior Driven Regularized Deep Learning For Sonar Image Classification
Deep learning has been recently shown to improve performance in the domain of synthetic aperture sonar (SAS) image classification. Given the constant resolution with range of a SAS, it is no surprise that deep learning techniques perform so well.
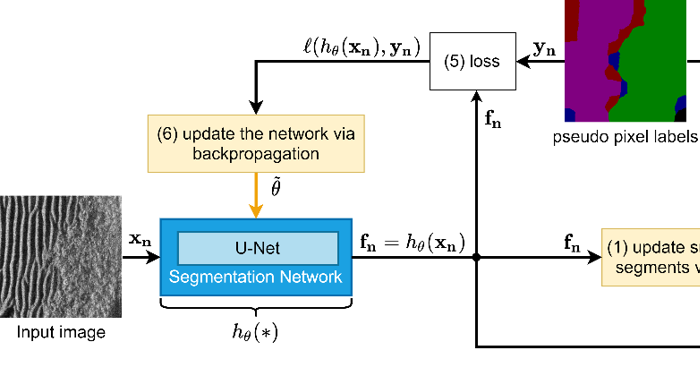
Iterative, Deep Synthetic Aperture Sonar Image Segmentation
Synthetic aperture sonar (SAS) systems produce high-resolution images of the seabed environment. Moreover, deep learning has demonstrated superior ability in finding robust features for automating imagery analysis. However, the success of deep learning is conditioned on having lots of labeled training data, but obtaining generous pixel-level annotations of SAS imagery is often practically infeasible.

2020 NTIRE-CVPR Challenge Selection
NonLocal Channel Attention For NonHomogeneous Image Dehazing
This project proposed a a novel network for dehazing for challenging benchmark image datasets of NTIRE'20 and NTIRE'18. The proposed networks `AtJwD' can outperform state-of-the-art alternatives, especially when recovering images corrupted by non-homogeneous haze.

2020 NTIRE-CVPR Challenge Selection
Ensemble Dehazing Networks For Non-Homogeneous Haze
A DenseNet based dehazing network focusing on the recovery of images corrupted with non-homogeneous haze by utilizating a weighted combination of outputs from different decoders.
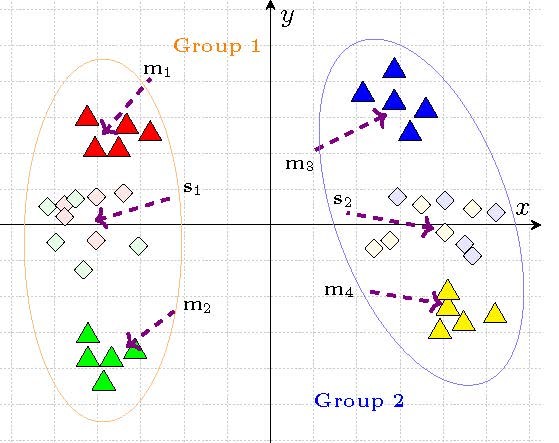
Group Based Deep Shared Feature Learning for Fine-grained Image Classification
Fine-grained image classification has emerged as a significant challenge because objects in such images have small inter-class visual differences but with large variations in pose, lighting, and viewpoints, etc.
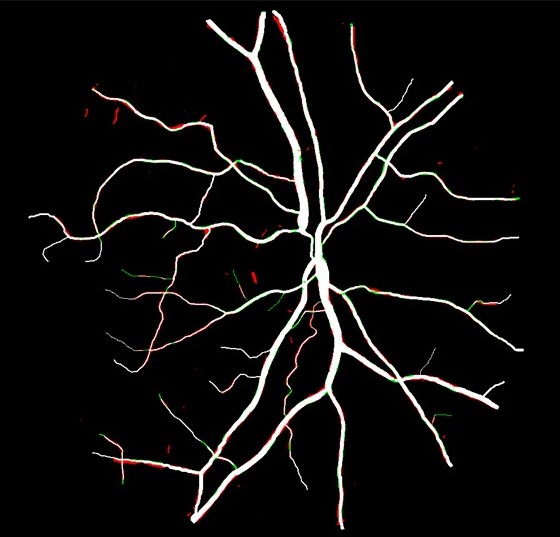
Deep Retinal Image Segmentation Under Geometrical Priors
Vessel segmentation of retinal images is a key diagnostic capability in ophthalmology. This problem faces several challenges including low contrast, variable vessel size and thickness, and presence of interfering pathology such as micro-aneurysms and hemorrhages.

CVPRW'19 WINNER!
Dense Scene Information Estimation Network For Dehazing
This project proposed a scene information estimation network for dehazing for challenging benchmark image datasets of NTIRE'19 and NTIRE'18. The proposed networks `At-DH' and `AtJ-DH' can outperform state-of-the-art alternatives, especially when recovering images corrupted by dense hazes.

CVPRW'19 RUNNER-UP!
Dense '123' Color Enhancement Dehazing Network
A DenseNet based dehazing network focusing on the recovery of the color information that comprises of: a common DenseNet based feature encoder whose output branches into three distinct DensetNet based decoders to yield estimates of the R, G and B color channels of the image.

Deep Wavelet Coefficients Prediction for Super-resolution
Recognizing that a wavelet transform provides a “coarse” as well as “detail” separation of image content, we design a deep CNN to predict the “missing details” of wavelet coefficients of the low-resolution images to obtain the Super-Resolution (SR) results, which we name Deep Wavelet Super-Resolution (DWSR).

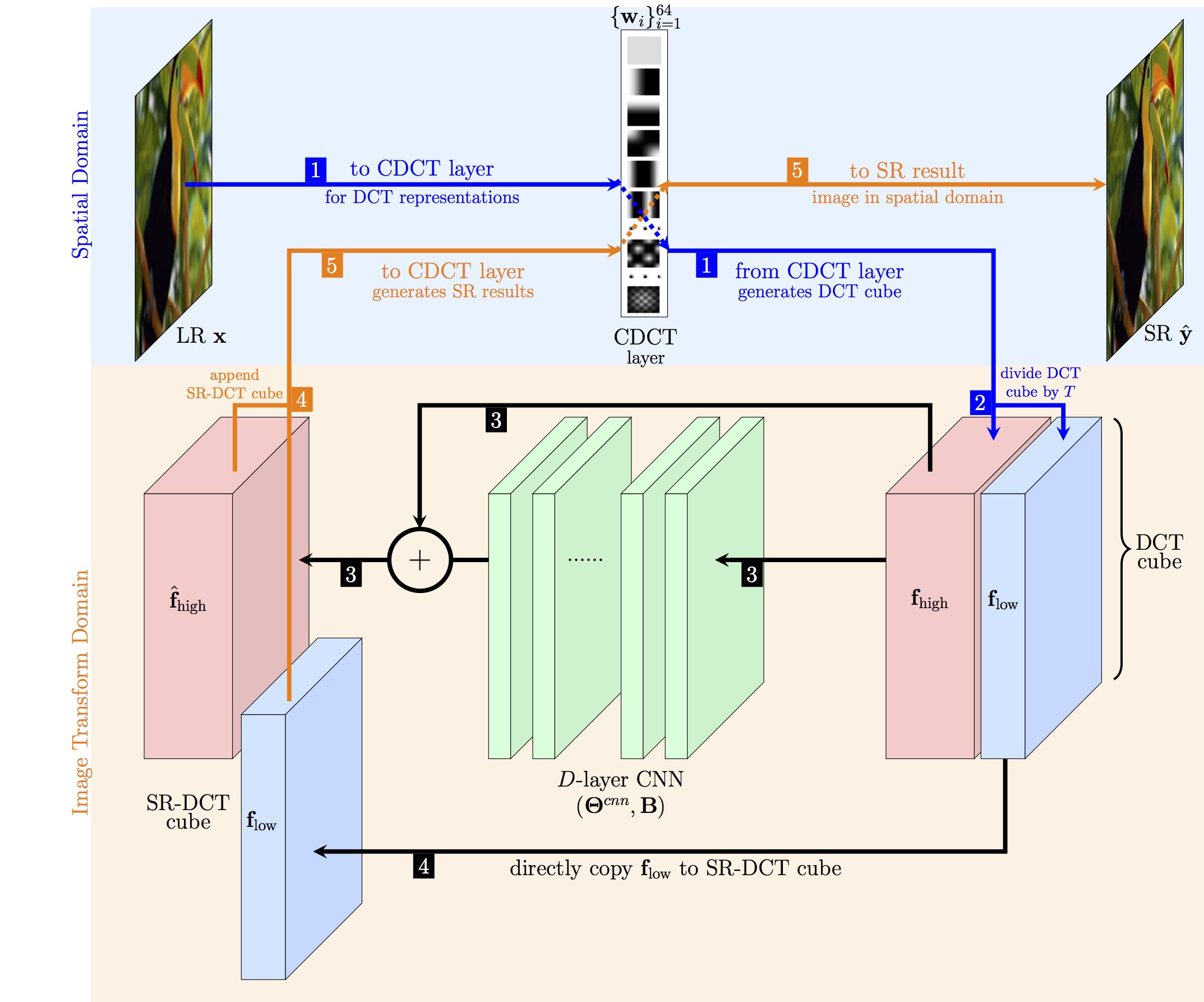
Orthogonally Regularized Deep Networks
We propose a novel network structure for learning the SR mapping function in an image transformation domain, specifically discrete cosine transformation (DCT). The DCT is integrated into the network structure as a convolutional DCT (CDCT) layer which is trainable while maintaining its orthogonality properties with the orthogonality constraints.

Deep Image Super-resolution Via Natural Image Priors
We explore the use of image structures and physically meaningful priors in deep structures in order to achieve bet- ter performance.
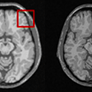
Deep MR Image Super-Resolution Using Structural Priors
Unlike regular optical imagery, for MR image super-resolution generous training is often unavailable. We therefore propose the use of image priors, namely a low-rank structure and a sharpness prior to enhance deep MR image super-resolution.
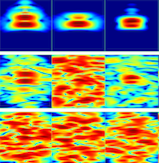
Simultaneous Decomposition and Classification Network
We propose a Simultaneous Decomposition and Classification Network (SDCN) to eliminate noise interference, enhancing the classification accuracy.
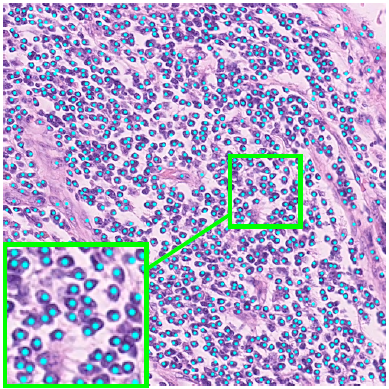
Deep Networks With Shape Priors For Nucleus Detection
Nuclei detection has been a topic of enduring interest with promising recent success shown by deep learning methods. These methods train for example convolutional neural networks (CNNs) with a training set of input images and known, labeled nuclei locations. Many of these methods are supplemented by spatial or morphological processing.